
PowerQuery【13】二つのファイルの不一致分のみ表示する(名寄せ_本格バージョン)
PowerQueryへのリンク
PowerQuery全体:PowerQuery【01】PowerQuery(パワークエリー)で出来ること
PowerQueryの手順:PowerQuery【02】PowerQuery(パワークエリー)の動かし方
PowerQueryのファイルの結合(マージ)の際に、結合の種類を「完全外部(両方の行すべて)」にすることで、
不一致分も含めた全てのテーブルを表示できるため、「不一致分のみ」のみの表示が可能です。
PowerQuery【12】二つのファイルの不一致分のみ表示する(名寄せ_簡易バージョン)
ですが、不一致分が大量にあるときは、「不一致分を上手く表示して、双方のキーを一度に表示できる工夫」が必要です。
これを上手く使うことで「2つのファイルの名寄せ」の手間がぐっと削減できる筈です。
↓こういうことがやりたいんです。(中々文章では上手く説明できないのです)
クリックで拡大します
VLOOKUP関数なら別々のシートでやるしか無かったのですが、不一致も一致も全て表示することが出来るPowerQueryのメリットを活かすとよりスピーディに名寄せが出来る訳です。
色々試して、今のところ、私の中では「これなら」と思っている手法です。
よろしければ、お試し下さい。
そこそこ複雑ですが、一度作ってしまえばプロセスを再利用できるのがPowerQueryの良いところ。
つまり、雛形を作ってしまうわけです。
かなり長いのですが、この通りにやれば、出来る筈です。
そして繰り返す時は、雛形に元名簿を貼るだけで、処理が「超時短」!
初回だけ、根気をもってお付き合いください。
本格バージョン
事例は簡易版と同じです。
所属と姓名と社員番号がある2種類の名簿があります。所属と姓名で合致状況を見て、それぞれの名簿の社員番号を紐付けます。
名寄せの際に考えるべきこと
【Excel】【PowerQuery】2つの名簿の姓名の名寄せ(例:新字体と旧字体混在)/「照合元」と「照合先」を見比べながら潰し込む
②PowerQueryで結合して、
1.元名簿(簡易版とほぼ同じ)と最終版
元データ
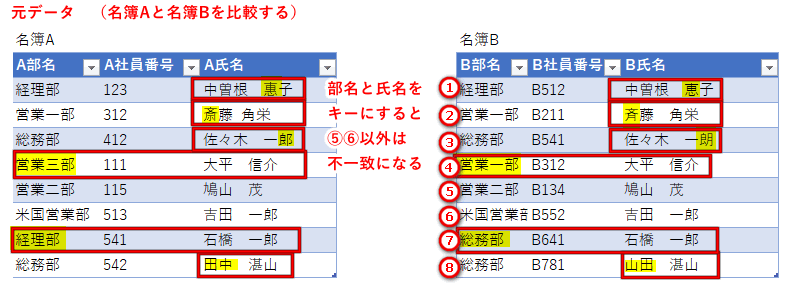
最終版
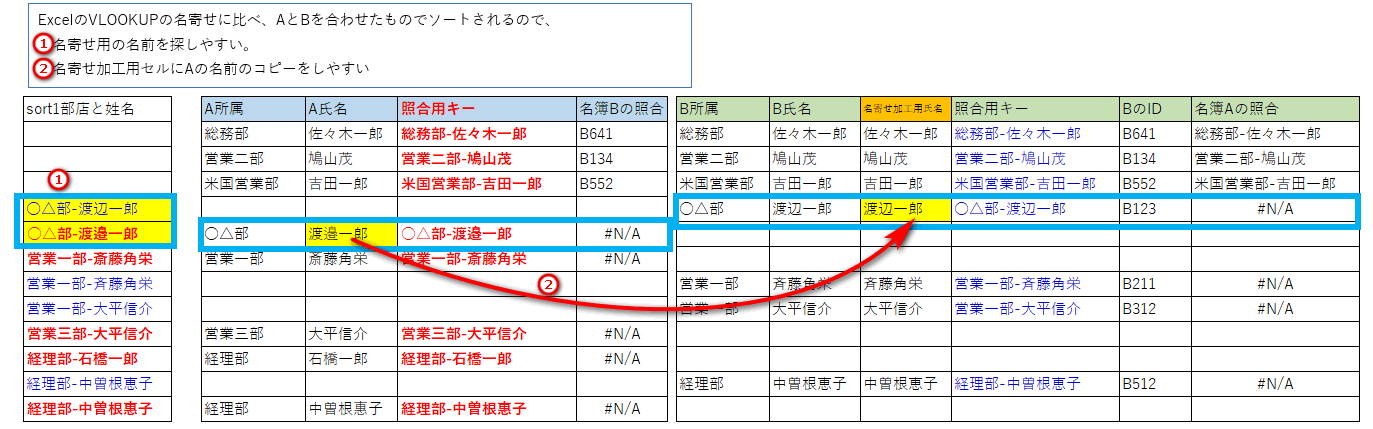
ExcelのVLOOKUPの名寄せに比べ、AとBを合わせたものでソートされるので、
①名寄せ用の名前を探しやすい。
②名寄せ加工用セルにAの名前のコピーをしやすい
名寄せの考え方
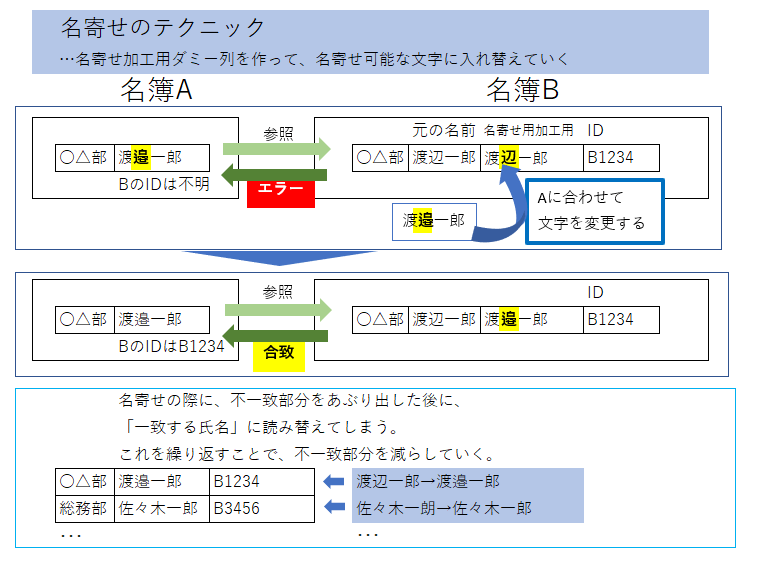
2.名簿AをPowerQueryエディタに読み込み、データクレンジングを実施し、列を追加する。
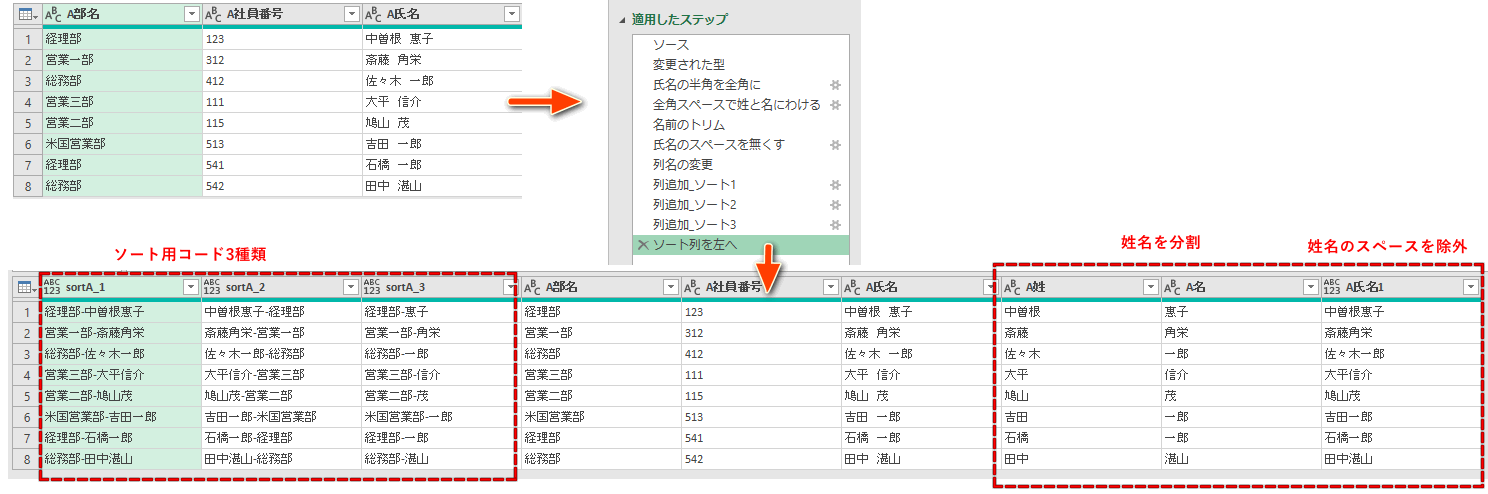
◆追加列(ソート列と照合用の姓名)
◆クエリ内のステップは以下の通りです。
| 適用したステップ名 | ←元のステップ名を変更したもの | 式 | |
| (1) | ソース | 自動で出来る | = Excel.CurrentWorkbook(){[Name=”テーブル1″]}[Content] |
| (2) | 変更された型 | 社員番号を文字型にした | = Table.TransformColumnTypes(ソース,{{“A部名”, type text}, {“A社員番号”, type text}, {“A氏名”, type text}}) |
| (3) | 氏名の全角を半角に | 列の追加/カスタム列出来た式を加工 | = Table.AddColumn(変更された型, “氏名スペース半角”, each Text.Replace([A氏名],” ”,” “)) |
| (4) | 半角スペースで姓と名にわける | 変換/ | = Table.SplitColumn(氏名の全角を半角に, “氏名スペース半角”, Splitter.SplitTextByDelimiter(” “, QuoteStyle.Csv), {“氏名スペース半角.1”, “氏名スペース半角.2”}) |
| (5) | 名前のトリム | = Table.TransformColumns(半角スペースで姓と名にわける,{{“氏名スペース半角.2”, Text.Trim, type text}}) | |
| (6) | 氏名のスペースを無くす | = Table.AddColumn(名前のトリム, “A氏名スペースなし”, each Text.Replace(Text.Replace([A氏名],” ”,””),” “,””)) | |
| (7) | 列名の変更 | = Table.RenameColumns(氏名のスペースを無くす,{{“氏名スペース全角.1”, “A姓”}, {“氏名スペース全角.2”, “A名”}, {“A氏名スペースなし”, “A氏名1”}}) | |
| (8) | 列追加_ソート1 | キーとソート用のコードを作る。 | = Table.AddColumn(列名の変更, “sortA_1″, each [A部名]&”-“&[A氏名1]) |
| (9) | 列追加_ソート2 | = Table.AddColumn(列追加_ソート1, “sortA_2″, each [A氏名1]&”-“&[A部名]) | |
| (10) | 列追加_ソート3 | = Table.AddColumn(列追加_ソート2, “sortA_3″, each [A部名]&”-“&[A名]) | |
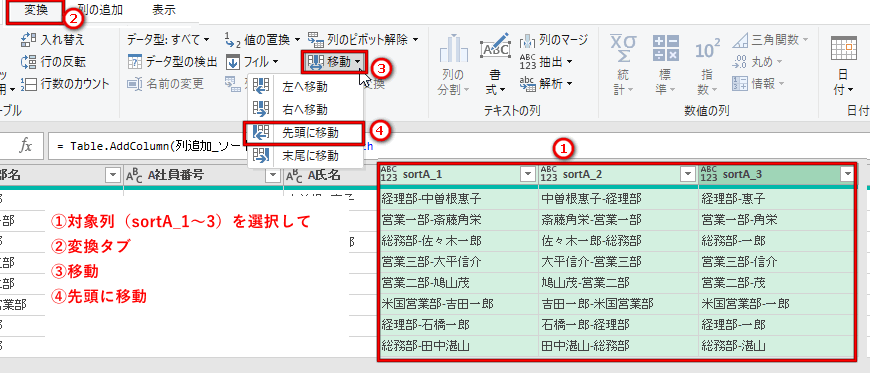
| (11) | ソート列を左へ | = Table.ReorderColumns(列追加_ソート3,{“sortA_1”, “sortA_2”, “sortA_3”, “A部名”, “A社員番号”, “A氏名”, “A姓”, “A名”, “A氏名1”}) |
(3)氏名の全角を半角に
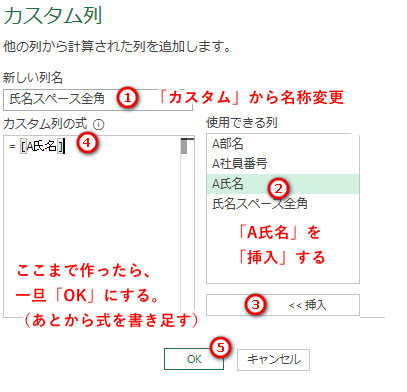
(上記のカスタム列ウィンドウで直しても良いのですが、私は式ウィンドウの方が入れやすいので)
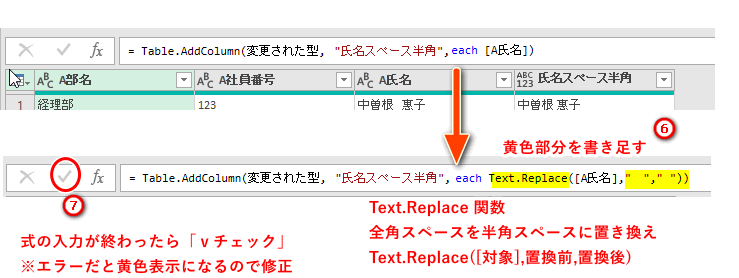
(4)半角スペースで姓と名にわける
②変換タブ
③列の分割
④区切り記号による分割
⑤区切り記号をスペースにして
⑥区切り記号の出現ごと
⑦OK
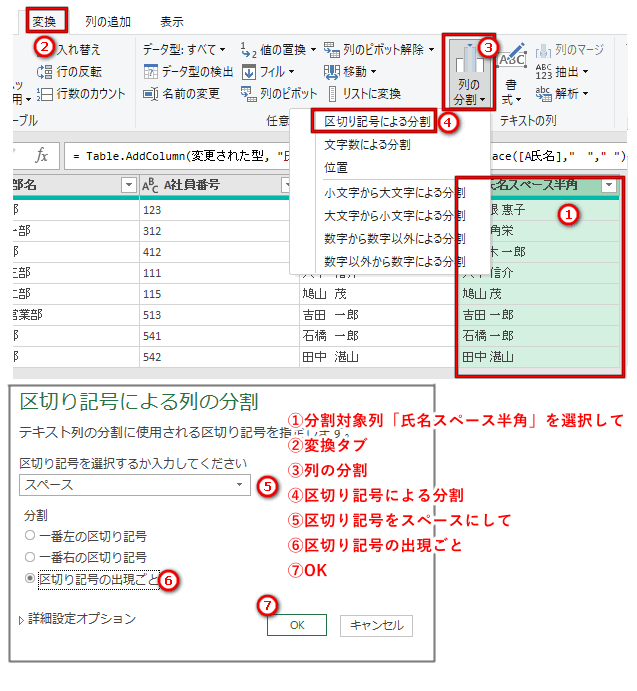
(5)名前のトリム

(6)氏名のスペースを無くす
Text.Replace文を書く
今回は、全角スペース→スペースなし」「半角スペース→スペースなし」の二重構造
(二回Replaceする)

(7)列名の変更

(8) 列追加_ソート1 を作成する
(9)(10)ソート2、ソート3も同様に作成する。
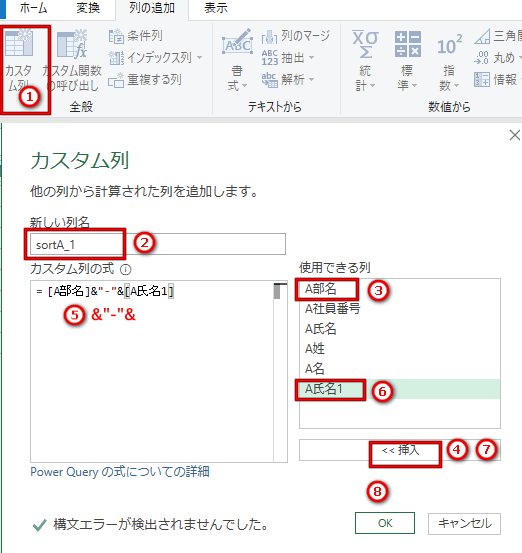
(11)ソート列を左へ
3.名簿Bも同様に処理する。
4.名簿Aと名簿Bを結合する。
| 適用したステップ名 | ←元のステップ名を変更したもの | 式 | |
| (1) | ソース | 自動で出来る
|
= Table.NestedJoin(名簿A, {“sortA_1”}, 名簿B, {“sortB_1”}, “名簿B”, JoinKind.FullOuter) |
| (2) | 展開された 名簿B | 名簿Bの展開ボタンを押すと出来る | = Table.ExpandTableColumn(ソース, “名簿B”, {“sortB_1”, “sortB_2”, “sortB_3”, “B部名”, “B社員番号”, “B氏名”, “B姓”, “B名”, “B氏名1”}, {“sortB_1”, “sortB_2”, “sortB_3”, “B部名”, “B社員番号”, “B氏名”, “B姓”, “B名”, “B氏名1”}) |
| (3) | 列追加_sot1_部名と姓名
|
・A社員番号null以外/かつ/B社員番号null以外 ※AとBどちらもnull以外(AとBが合致するとき)→null ・A社員番号null → sortB_1 Aが無い時はBの情報 ・B社員番号null → sortA_1 Bが無い時はAの情報 例:○○部-吉田角栄 |
= Table.AddColumn(#”展開された 名簿B”, “sort1部店と姓名”, each if ([A社員番号] <> null and [B社員番号] <>null) then null else if [A社員番号] = null then [sortB_1] else if [B社員番号] = null then [sortA_1] else null) |
| (4) | 列追加_sot2_姓名と部名 | (3)と同様に式を書く 例:吉田角栄-○○部 |
= Table.AddColumn(列追加_sot1_部名と姓名, “sort2姓名と部名”,each if ([A社員番号] <> null and [B社員番号] <>null) then null else if [A社員番号] = null then [sortB_2] else if [B社員番号] = null then [sortA_2] else null) |
| (5) | 列追加_sot3_部名と名前 | (3)と様に式を書く 例:○○部-花子 |
= Table.AddColumn(列追加_sot2_姓名と部名, “sort3部名と名前”,each if ([A社員番号] <> null and [B社員番号] <>null) then null else if [A社員番号] = null then [sortB_3] else if [B社員番号] = null then [sortA_3] else null) |
| (6) | sort列を左に | 「2-(11)ソート列を左へ」と同様にソート列3つを選んで/変換タブ/移動/④先頭に移動 | = Table.ReorderColumns(列追加_sot3_部名と名前,{“sort1部店と姓名”, “sort2姓名と部名”, “sort3部名と名前”, “sortA_1”, “sortA_2”, “sortA_3”, “A部名”, “A社員番号”, “A氏名”, “A姓”, “A名”, “A氏名1”, “sortB_1”, “sortB_2”, “sortB_3”, “B部名”, “B社員番号”, “B氏名”, “B姓”, “B名”, “B氏名1”}) |
| (7) | sort1で並び替え | sort1を選択して、▼をクリック/昇順に並び替え | = Table.Sort(sort列を左に,{{“sort1部店と姓名”, Order.Ascending}}) |
| (8) | 不要な列の削除 | “sortA_2”, “sortA_3”, “A姓”, “A名”, “sortB_1”, “sortB_2”, “sortB_3”, “B姓”, “B名” を選択して、ホーム/列の削除 |
= Table.RemoveColumns(sort1で並び替え,{“sortA_2”, “sortA_3”, “A姓”, “A名”, “sortB_1”, “sortB_2”, “sortB_3”, “B姓”, “B名”}) |
(3) 列追加_sot1_部名と姓名について
「列の追加」タブ/条件列/とりあえずそれらしい式を入れる
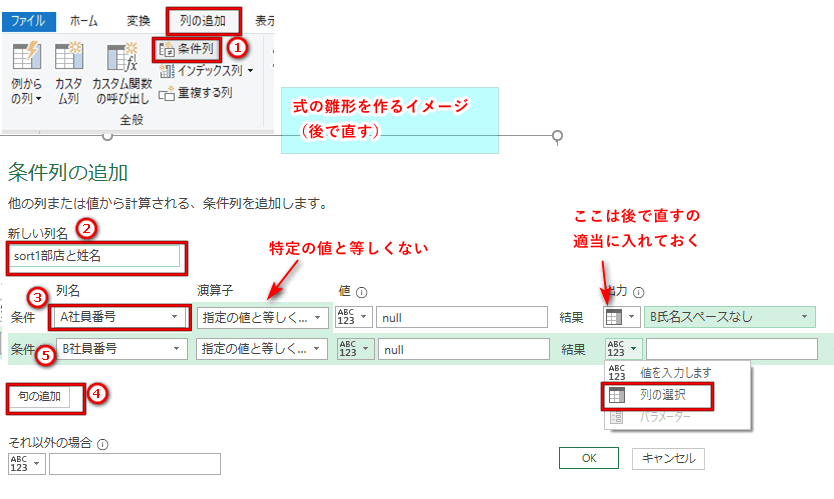
式を直す

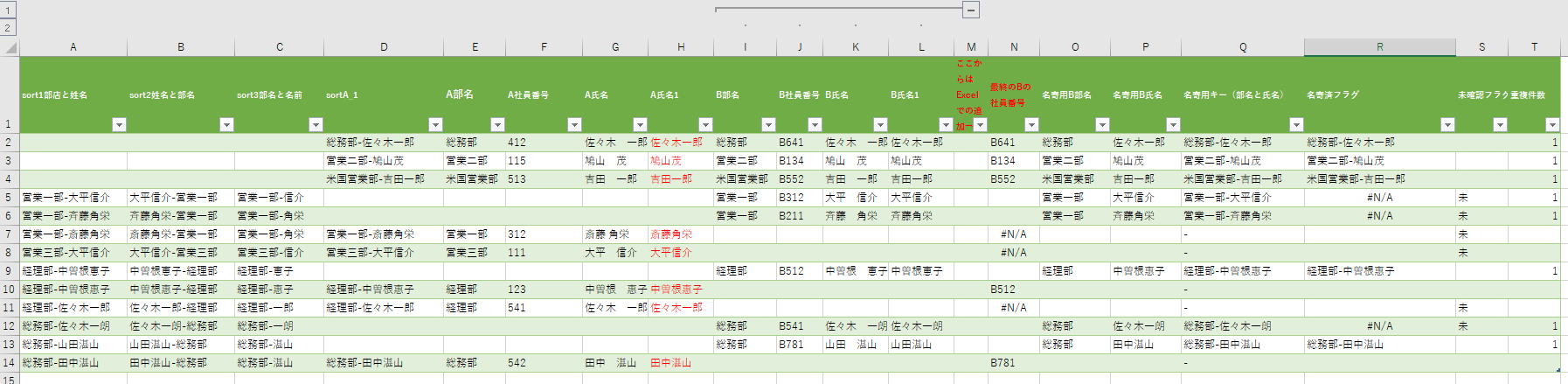
5.Excel上での作業(仕込み)
式を書くと勝手に変わるので意識する必要はありません。
| sort1部名と姓名 | |
| sort2姓名と部名 | |
| sort3部名と名前 | |
| sortA_1 | |
| A部名 | |
| A社員番号 | |
| A氏名 | |
| A氏名1 | |
| B部名 | データタブ/グループ化
…たたんで非表示できるようにする |
| B社員番号 | |
| B氏名 | |
| B氏名1 | |
| ここからはExcelでの追加→ | これ不要なのですが、後でみた時の、分かり易さのために追加してみました(この列はブランクです) |
| 最終のBの社員番号 | VLOOKUPで何とかしようと思ったのですが、複雑になりすぎるので、INDEX(MATCH)の関数の組み合わせにしました。XLOOKUPが使える環境ならその方が良いです。 |
| =IF([@A社員番号]=””,””,INDEX(J:J,MATCH([@[sortA_1]],Q:Q,0))) | |
| 名寄用B部名 | いったん、「B部名」をそのままコピーする |
| 名寄用B氏名 | いったん、「B氏名」をそのままコピーする ここを変更して、名寄せ確定データを増やしていく |
| 名寄用キー(部名と氏名) | 修正した名寄用のB部名とB氏名のキーを作る
(上の名寄用の部名と氏名を修正すると、変わっていく) |
| =[@名寄用B部名]&”-“&[@名寄用B氏名] | |
| 例:営業部-吉田角栄 | |
| 名寄済フラグ | Bのデータが入っている行のみ処理する。加工した名寄せキーと sortA_1(Aの部名-氏名)をVLOOKUPする |
| =IF([@名寄用B部名]=””,””,VLOOKUP([@名寄用キー(部名と氏名)],D:D,1,0)) | |
| 例:営業二部-鳩山茂 | |
| 未確認フラグ | 「最終のBの社員番号」と「名寄済フラグ」のいずれかがエラーだった時、「未」を表示する |
| =IF(ISERROR([@最終のBの社員番号]&[@名寄済フラグ])=TRUE,”未”,””) | |
| 例:「未」or「 」 | |
| 重複件数 | 「名寄用キー(部名と氏名)」に重複が無いか(「1」か「ブランク」になる筈) |
| =IF([@名寄用キー(部名と氏名)]=”-“,””,COUNTIF(Q:Q,[@名寄用キー(部名と氏名)])) | |
| 例:「1」or「 」or「2以上の数値」…2以上なら個別トレースが必要 |
↓クリックすると拡大します
6.Excel上での作業(実作業)
さて、名寄せ作業です。(スクリーンショットは小さいですが、クリックすると拡大します)
ソート1により「部名と名前」の「名寄せ分」のA名簿とB名簿のデータが近くなっているので、
その名前を寄せていきます。(説明しずらいので、スクリーンショットで示します)
ExcelのVLOOKUPの名寄せに比べ、AとBを合わせたものでソートされるので、以下が便利なのです。
・名寄せ用の名前を探しやすい。
・名寄せ加工用セルにAの名前のコピーをしやすい
さて実際の画面です。
(1)まず初期画面です。
Bの元データはグループ化しているので、非表示にする。

(2)一致分だけは、「未確認フラグ」がブランクになるので、フィルタをかけて「未」分を表示する。
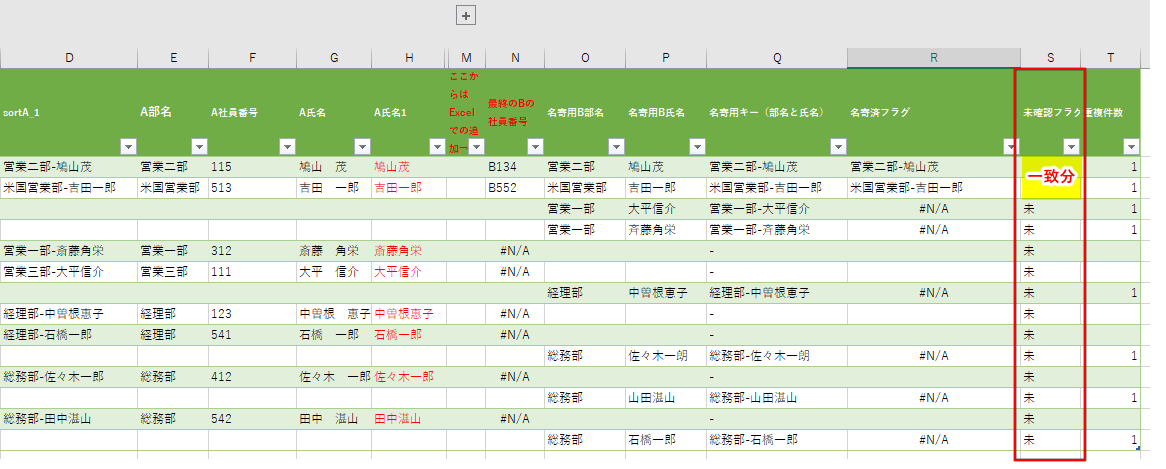
(3)「未」分のみを表示したところ
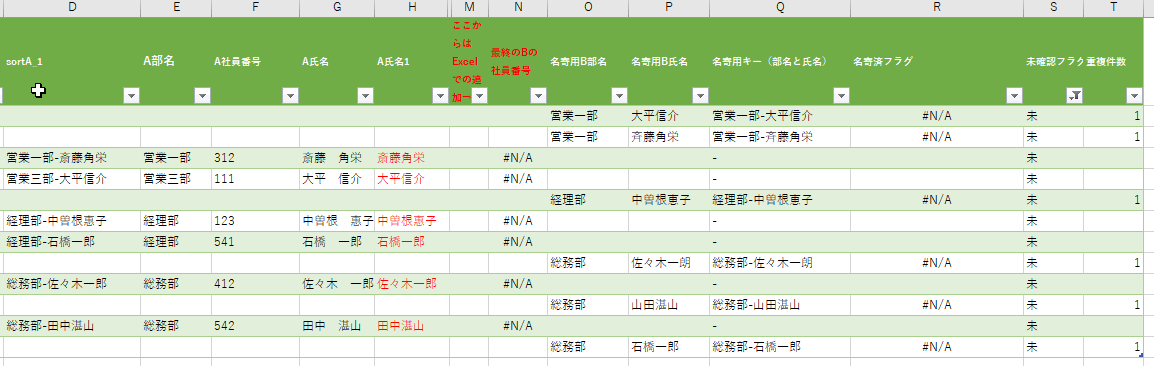
(4)「sort1部名-氏名」にフォーカスを当てて名寄せ
①「未確認フラグ」列のフィルタを「未」で抽出する
②A氏名1を赤文字にする
③名寄せ可能な場合、「A氏名1」を「名寄用B氏名」にコピーする
④名寄せ出来たので「未」の文字が消える
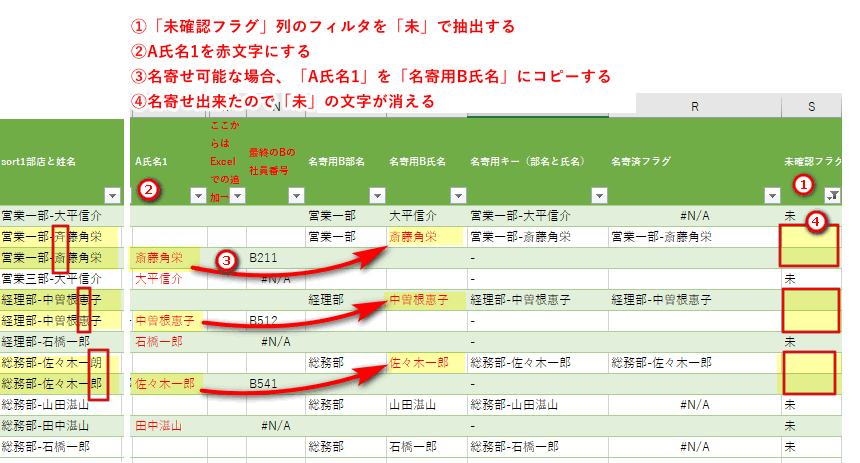
(5)「sort2氏名-部名」(異動しているケース)にフォーカスを当てて名寄せ

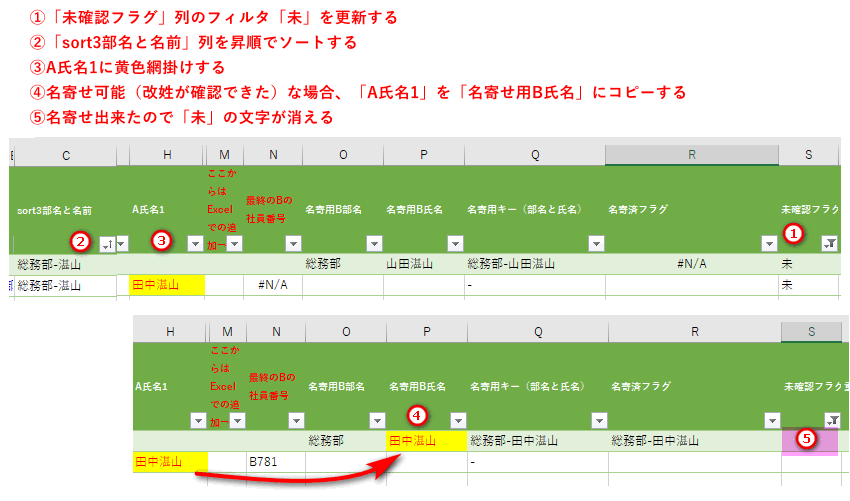
(6)「sort3部名-名前(下の名前)」(改姓しているケース)にフォーカスを当てて名寄せ
①「未確認フラグ」列のフィルタ「未」を更新する
②「sort3部名と名前」列を昇順でソートする
③A氏名1に黄色網掛けする
④名寄せ可能(改姓が確認できた)な場合、「A氏名1」を「名寄せ用B氏名」にコピーする
⑤名寄せ出来たので「未」の文字が消える
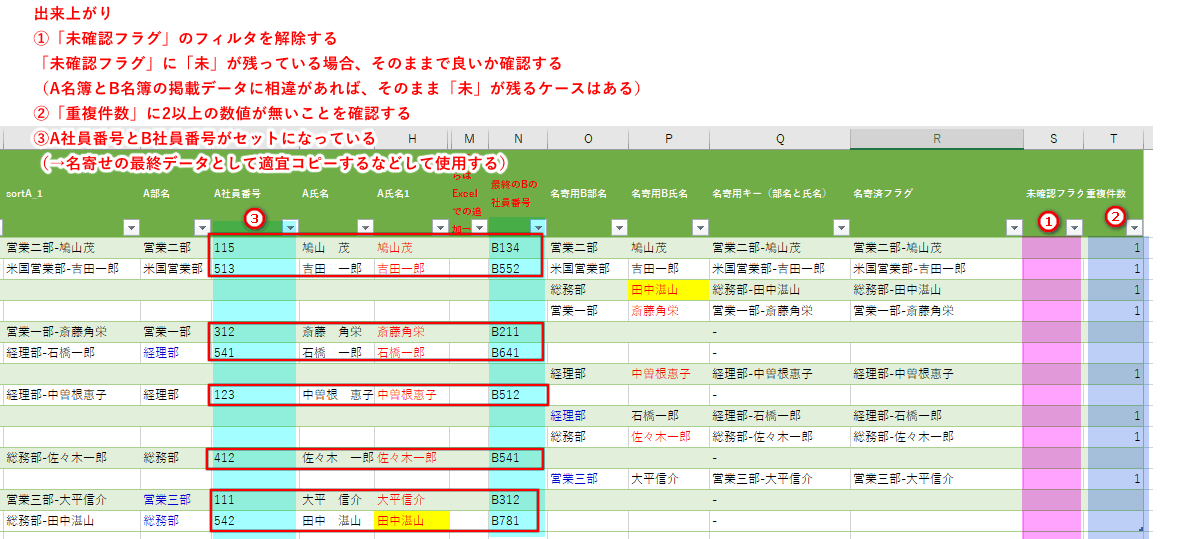
(7)出来上がり
①「未確認フラグ」のフィルタを解除する
「未確認フラグ」に「未」が残っている場合、そのままで良いか確認する
(A名簿とB名簿の掲載データに相違があれば、そのまま「未」が残るケースはある)
②「重複件数」に2以上の数値が無いことを確認する
③A社員番号とB社員番号がセットになっている
(→名寄せの最終データとして適宜コピーするなどして使用する)
以上、ずいぶん長いのですが、いったん作れば、何度も使えます。
(PowerQuery以外の部分のExcelの式も残ります)
よろしければお試し下さい。

